이지 딥러닝 - 혁펜하임 | Easy! 딥러닝 4강 Train · Validation · Test, K-fold
[AI 인공지능 머신러닝 딥러닝] - 이지 딥러닝 - 혁펜하임 | Easy! 딥러닝 - 무료 강의 및 책 소개
이지 딥러닝 - 혁펜하임 | Easy! 딥러닝 - 무료 강의 및 책 소개
한국어로 딥러닝 공부해봤다는 사람중에 안들어 본 사람이 없을것 같은 이지 딥러닝 시리즈 입니다. 이 강의는 유투브로 제공되며 책도 있습니다. 이지 딥러닝 유투브 강의이지 딥러닝 유투브
inner-game.tistory.com
[Easy! 딥러닝] 4-1강. Validation 데이터가 꼭 필요한 이유 | 테스트 데이터와 차이점은??
이 4-1강의 핵심은 “테스트 데이터는 ‘실전 점수 확인용’으로만 쓰이고, 학습 중에 언제 멈출지·모델 구조·하이퍼파라미터를 정할 때는 반드시 따로 떼어 둔 밸리데이션 데이터로 판단해야 과적합을 막고 일반화 성능을 제대로 볼 수 있다”는 점입니다.
Train · Validation · Test 역할
영상에서는 세 가지 데이터를 이렇게 구분합니다.
- Training data: 파라미터(웨이트, 바이어스) 학습용 데이터. 역전파로 직접 그라디언트를 계산해 업데이트에 사용.
- Validation data: 학습에는 참여하지 않지만,
-- 에폭 수, 러닝레이트, 모델 구조(레이어·노드 수) 같은 하이퍼파라미터 선택
-- 언제 학습을 멈출지(early stopping) 를 결정할 때 성능을 보는 기준으로 사용.
- Test data: 최종적으로 “완성된 모델이 처음 보는 데이터에서 얼마나 잘 하는지”를 평가하는, 단 한 번 사용하는 실전용 평가 세트.
트레인/밸리데이션/테스트를 60–80% / 10–20% / 10–20% 정도로 나누는 것이 흔한 출발점이라는 것도 일반적으로 알려져 있습니다.
왜 테스트 데이터로 에폭·모델을 고르면 안 되는가
트레이닝 로스는 에폭이 늘수록 계속 감소하지만, 일정 시점 이후에는 테스트·밸리데이션 로스가 다시 증가하는 구간이 생깁니다.
- 이 구간부터는 훈련 데이터에 “외우기(오버피팅)”를 시작한 것이고,
- 실제 처음 보는 데이터에 대한 성능은 오히려 나빠집니다.
이때 “테스트 로스가 최소가 되는 에폭에서 멈추자”라고 하면,
- 테스트 세트에 가장 잘 맞는 에폭을 골라 버리는 것이고,
- 결국 테스트 세트도 일종의 훈련(튜닝)에 사용한 셈이라, 진짜 보지 못한 새로운 데이터에 대한 일반화 성능을 제대로 추정할 수 없게 됩니다.
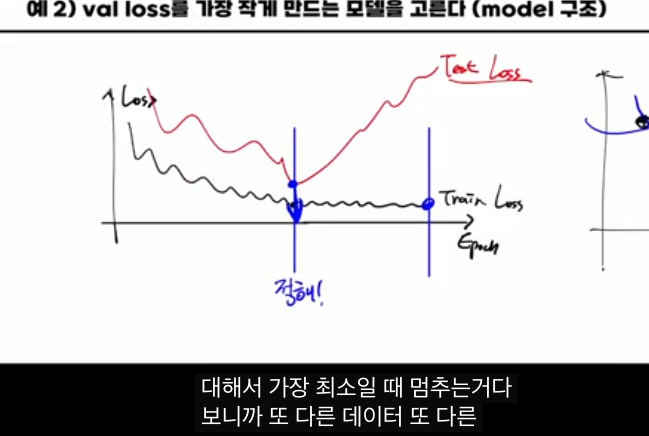
그래서 테스트 세트는 오직 최종 한 번의 평가에만 쓰고,
- 에폭 선택,
- 모델 구조/하이퍼파라미터 선택은 반드시 밸리데이션 세트 기준으로 해야 한다고 설명합니다.
밸리데이션으로 하는 일: Early Stopping과 모델 선택
밸리데이션 데이터는 학습 중 “모의고사” 역할을 합니다.
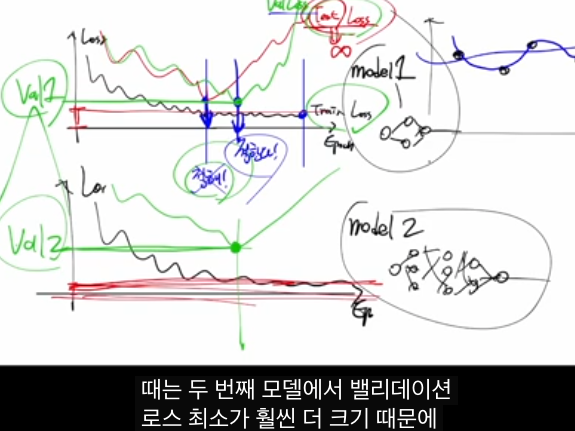
- 에폭 vs 로스 그래프에서,
-- Train loss는 계속 감소.
-- Validation loss는 어느 지점까지 내려갔다가 다시 올라가면, 그 최소점 근처 에폭에서 학습을 멈추는 것이 좋다 → Early stopping.
- 서로 다른 모델(예: 작고 단순한 MLP vs 크고 복잡한 MLP)을 여러 개 학습시킨 후,
-- 각 모델마다 최소 validation loss 값을 비교해서
-- 가장 작은 validation loss를 가진 모델을 최종 모델로 선택합니다.

이렇게 하면,
- Training set은 파라미터 학습용,
- Validation set은 하이퍼파라미터·모델 구조 선택용,
- Test set은 최종 일반화 성능 측정용
이라는 역할 분담이 명확해지고, 과적합을 줄이면서 실전에 강한 모델을 만들 수 있습니다.

[Easy! 딥러닝] 4-2강. K-fold Cross Validation (교차 검증) 진짜 쉽게 설명해 드려요
이 강의의 핵심은 “데이터가 적어서 밸리데이션 분할이 불안정할 때, K-fold 교차검증으로 ‘여러 가지 train/val 쪼개기’를 전부 돌린 뒤 평균 밸리데이션 성능을 쓰면 편향이 줄고, 하이퍼파라미터 선택도 더 믿을 만해진다”는 점입니다.

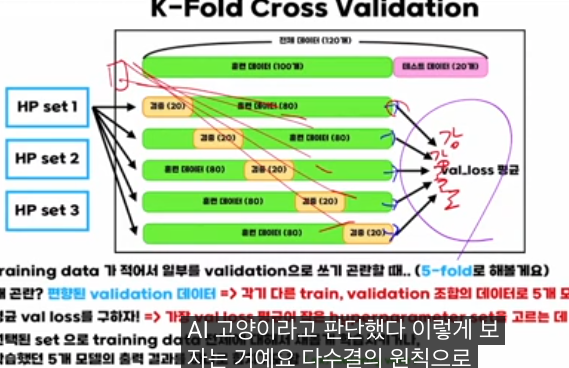
K-fold 교차검증 개념
예를 들어 전체 120개 중 100개를 훈련, 20개를 밸리데이션에 쓰면, 그 “앞의 20개”가 우연히 전부 강아지일 수도 있어서, 밸리데이션 로스가 강아지 쪽으로 편향됩니다. 이렇게 한 번만 쪼개면 그 20개에 과하게 의존하게 되죠.
K-fold 교차검증에서는 훈련 데이터를 K등분한 뒤,
- 각 fold를 한 번씩 밸리데이션으로 돌려가며
- K번 학습·평가를 해서 밸리데이션 로스를 K K개 얻고
- 그것들의 평균을 “그 하이퍼파라미터 세트의 성능”으로 봅니다.
이렇게 하면 “특정 20개에만 치우친 운빨”이 줄고, 데이터의 다양한 부분을 밸리데이션으로 사용하므로 더 안정적인 일반화 추정이 가능합니다.

하이퍼파라미터 선택과 앙상블 활용
강의에서는 여러 하이퍼파라미터 세트(예: 세트 1, 2, 3)를 준비하고,
- 각 세트마다 K개의 모델을 학습해
- 그 세트의 평균 밸리데이션 로스를 계산한 뒤
- 평균이 가장 작은 세트를 최종 하이퍼파라미터로 선택하자고 설명합니다.
그 다음 단계에서는 두 가지 실전 패턴을 소개합니다.
- 선택된 하이퍼파라미터로 전체 훈련 데이터(100개)를 다시 학습해 하나의 최종 모델을 만든다.
- 또는, 교차검증에서 나온 K개 모델을 그대로 앙상블(majority vote, soft voting) 해서 예측에 사용한다.
요약하면, K-fold 교차검증은
- 데이터가 적을 때 밸리데이션 분할의 편향을 줄이고
- 하이퍼파라미터 선택과 모델 평가를 더 신뢰할 수 있게 만드는 표준 기법이라는 점을 이 강의가 직관적으로 설명하는 것입니다.

[AI 인공지능 머신러닝 딥러닝] - 이지 딥러닝 - 혁펜하임 | Easy! 딥러닝 5강 - linear activation, 역전파(Backpropagation)
이지 딥러닝 - 혁펜하임 | Easy! 딥러닝 5강 - linear activation, 역전파(Backpropagation)
[AI 인공지능 머신러닝 딥러닝] - 이지 딥러닝 - 혁펜하임 | Easy! 딥러닝 - 무료 강의 및 책 소개 이지 딥러닝 - 혁펜하임 | Easy! 딥러닝 - 무료 강의 및 책 소개한국어로 딥러닝 공부해봤다는 사람중
inner-game.tistory.com
공유하기
'AI 인공지능 머신러닝 딥러닝' 의 관련글
-
혁펜하임의 “탄탄한” 컨벡스 최적화 (Convex Optimization) 강의 소개 2025.12.08더보기
-
이지 딥러닝 - 혁펜하임 | Easy! 딥러닝 1강 - 지도 학습과 비지도 학습, 자기 지도 학습, 강화 학습 2025.12.07더보기
-
이지 딥러닝 - 혁펜하임 | Easy! 딥러닝 3강 - 확률적 경사 하강법 (SGD: Stochastic Gradient Descent), momentum, RMSProp , Adam (Adaptive Moment Estimation) 완벽 정리 2025.12.07더보기
-
이지 딥러닝 - 혁펜하임 | Easy! 딥러닝 2강 그래디언트와 러닝 레이트 SGD, 로컬미니마 2025.12.07더보기