이지 딥러닝 - 혁펜하임 | Easy! 딥러닝 3강 - 확률적 경사 하강법 (SGD: Stochastic Gradient Descent), momentum, RMSProp , Adam (Adaptive Moment Estimation) 완벽 정리
[AI 인공지능 머신러닝 딥러닝] - 이지 딥러닝 - 혁펜하임 | Easy! 딥러닝 - 무료 강의 및 책 소개
이지 딥러닝 - 혁펜하임 | Easy! 딥러닝 - 무료 강의 및 책 소개
한국어로 딥러닝 공부해봤다는 사람중에 안들어 본 사람이 없을것 같은 이지 딥러닝 시리즈 입니다. 이 강의는 유투브로 제공되며 책도 있습니다. 이지 딥러닝 유투브 강의이지 딥러닝 유투브
inner-game.tistory.com
[Easy! 딥러닝] 3-1강. Gradient Descent 의 두 가지 치명적 단점
이 3-1강에서 말하는 핵심은 “순수 Gradient Descent(배치 GD)는 (1) 한 스텝이 너무 느리고, (2) 거의 확실히 ‘가장 가까운 로컬 미니멈’에 갇힌다”는 두 가지 치명적 단점입니다.
첫 번째 단점: 한 스텝이 너무 느림
배치 Gradient Descent는 매 스텝마다 전체 데이터에 대해 로스와 그라디언트(편미분)를 전부 계산한 뒤 파라미터를 한 번 업데이트합니다.
- 데이터가 100만 개면, 그라디언트를 한 번 구할 때 이미 100만 개 샘플에 대한 합을 계산해야 하므로, 한 스텝 자체가 매우 무거운 연산입니다.
- 그런데 수렴하려면 이런 스텝을 수천·수만 번 반복해야 하므로, 실전 규모 데이터·딥러닝 모델에서는 사실상 너무 느려서 쓰기 어렵습니다.
즉, “모든 데이터를 다 고려해서 굉장히 신중하게 방향을 잡는 대신, 그 신중함 때문에 한 걸음을 떼는 데 시간이 너무 오래 걸린다”가 첫 번째 문제입니다.
두 번째 단점: 가장 가까운 로컬 미니멈에 갇힘
비선형 신경망의 로스 지형은 곳곳에 웅덩이(로컬 미니멈)가 많은 비볼록(non-convex) 함수입니다. 배치 GD는
- 항상 “현재 위치에서 로스를 가장 많이 줄이는 방향(−gradient)”으로만 움직이기 때문에
- 시작 위치 근처의 로컬 미니멈에 수렴할 수밖에 없습니다.
영상에서는 “결혼 상대” 비유와 함께,
- 가중치를 랜덤하게 0 근처 쓰레기 값으로 초기화하기 때문에, 처음 위치 근처에 있는 로컬 미니멈이 진짜 좋은(글로벌에 가까운) 해일 확률은 극히 낮다고 설명합니다.
- 그럼에도 GD는 거기서 바로 멈춰 버리므로, 충분히 탐험도 못 해 보고 “처음 만난 로컬 미니멈에 결혼해 버리는” 꼴이 된다는 비판을 합니다.
요약하면, 배치 Gradient Descent는
- 연산량 면에서 너무 느리고
- 탐색 면에서도 가장 가까운 로컬 미니멈에 쉽게 갇히는 한계를 가진다는 것이고, 이 두 문제를 완화하기 위해 다음 강의에서 SGD(확률적 GD)와 그 변형들을 소개하겠다는 흐름으로 이어집니다.
[Easy! 딥러닝] 3-2강. 확률적 경사 하강법 (SGD: Stochastic Gradient Descent) 주머니 예시로 쉽게 설명해 드려요
이 3-2강의 핵심은 “SGD는 데이터를 하나씩(또는 아주 적은 수만) 랜덤하게 뽑아 그라디언트를 계산해 업데이트하기 때문에, (1) 훨씬 빠르고, (2) 노이즈 덕분에 로컬 미니멈에서 빠져나갈 기회도 생긴다”는 점입니다.
SGD의 아이디어와 절차
영상에서는 주머니 비유로 SGD를 설명합니다.

- 주머니 안에 각 데이터에 대한 에러 제곱 ( e i 2 ) (e i 2 )을 넣어 둔다고 생각합니다.
- 한 번 업데이트할 때마다 주머니에서 데이터 하나를 랜덤하게 뽑고, 그 데이터만으로 로스와 그라디언트를 계산해 파라미터를 한 스텝 업데이트합니다.
- 다시 그 데이터를 주머니에 넣고 섞은 뒤, 또 하나를 뽑아 같은 과정을 반복합니다.
즉, 배치 GD가 “전체 데이터의 평균 그라디언트”를 쓰는 반면, SGD는 “무작위 한 샘플의 그라디언트”를 사용하는 확률적 근사라는 관점입니다.
배치 GD 대비 장점: 속도와 로컬 미니멈 탈출 기회

1. 훨씬 빠른 업데이트
- 배치 GD: 한 스텝에 모든 샘플을 다 써서 그라디언트를 계산하므로, 샘플이 N N개면 한 스텝 계산 비용이 O ( N ) O(N)입니다.
- SGD: 매 스텝마다 샘플 하나만 쓰기 때문에, 한 스텝 비용은 O ( 1 ) O(1)이고 훨씬 자주/빨리 업데이트할 수 있습니다.
2. 로컬 미니멈에서 빠져나갈 수 있는 노이즈
- 각 샘플마다 로스 지형과 그라디언트 방향이 조금씩 다르기 때문에, SGD의 경로는 매번 지그재그로 흔들리는 노이즈가 섞인 형태가 됩니다.
- 이 노이즈 때문에 특정 로컬 미니멈 근처라도 계속 왔다 갔다 하다가, 운 좋게 더 낮은 골짜기(더 좋은 로컬 미니멈 또는 글로벌 미니멈)로 넘어갈 기회가 생깁니다.
- 영상도 “무조건 글로벌을 찾는 건 아니지만, 배치 GD처럼 ‘항상 처음 근처 로컬에만 고이는’ 것보다는, 탈출 기회를 제공한다”는 정도로 표현합니다.
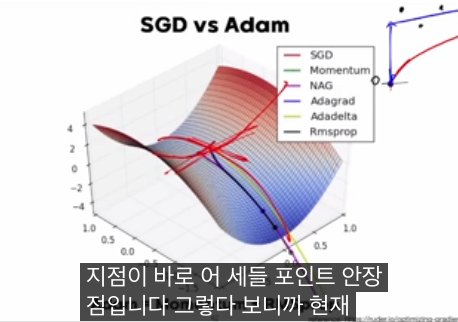
왜 경로가 최소점을 곧장 향하지 않고 삐뚤게 보이는가?
교과서 그림에서 SGD 경로가 최소점을 곧장 향하지 않고 삐뚤삐뚤한 이유를 영상에서 따로 짚습니다.
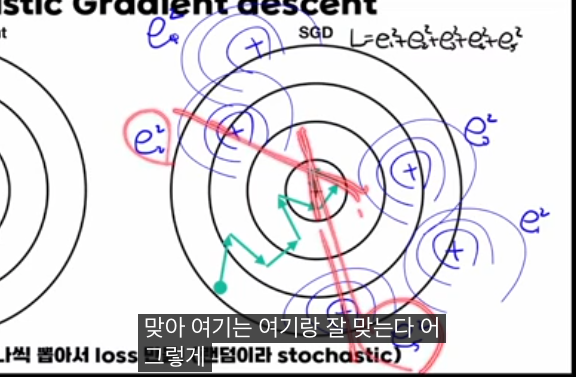
- 검은 등고선은 “전체 데이터에 대한 로스”의 등고선이고, 그에 대한 그래디언트는 배치 GD가 따라가는 방향입니다.
- 반면, 매번 SGD가 사용하는 그라디언트는 “랜덤하게 선택된 한 샘플에 대한 로스”의 그래디언트입니다.
- 이 한 샘플 기준으로 보면, SGD도 그 샘플의 로스를 가장 빨리 줄이는 방향(그 샘플의 최소점 방향)을 정확히 따라가지만, 전체 로스 기준으로 보면 그 방향이 항상 전역 최소를 곧장 향하는 건 아닙니다.
그래서 등고선 그림에서 SGD 경로가 전체 최소점을 향해 직선처럼 가지 않고, 여러 샘플의 미니멀을 반영하며 랜덤 워크처럼 지그재그로 수렴하는 모습이 나타납니다.
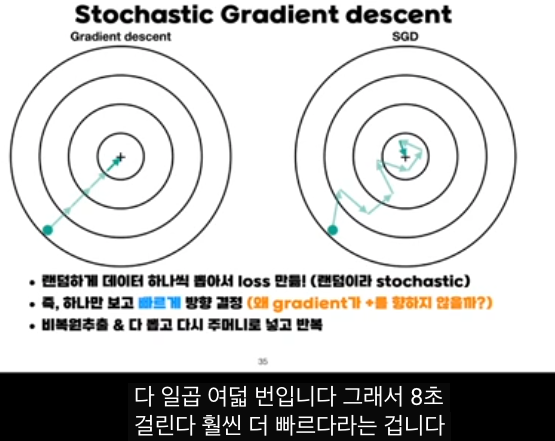
요약 관점
- 정의: SGD = 매 스텝마다 데이터 하나(또는 매우 작은 배치)를 랜덤 샘플링해 그라디언트를 근사하고, 그걸로 파라미터를 업데이트하는 방법입니다.
- 장점:
-- 큰 데이터셋에서도 계산·메모리 효율이 매우 좋고, 업데이트가 빠르다.
-- 그라디언트 노이즈 덕분에, 배치 GD보다 로컬 미니멈·새들 포인트를 빠져나갈 가능성이 크다.

영상 이후에는 이 SGD를 일반화한 미니배치 GD, 모멘텀, Adam 같은 최적화 알고리즘으로 이어지는 흐름을 잡으면 이해가 자연스럽게 이어집니다.
[Easy! 딥러닝] 3-3강. mini-batch GD & 배치 크기를 무작정 키우면 안 되는 이유
이 3-3강의 핵심은 “미니배치 SGD는 ‘배치 GD ↔ SGD’ 사이의 중간 해법이고, 배치 크기를 너무 키우면 (GPU로 빨라져도) 일반화 성능과 탐색 성질이 나빠질 수 있어 적당한 배치 크기 선택과 러닝레이트·웜업이 중요하다”는 점입니다.

미니배치 SGD의 개념
강의에서는 SGD와 배치 GD 사이를 이렇게 정리합니다.
- SGD: 배치 크기 = 1. 샘플 하나씩 뽑아 그라디언트 계산 후 업데이트. 매우 빠르지만 너무 “갈지자”이고 노이즈가 큼.
- 배치 GD: 배치 크기 = 전체 데이터 N. 전체 평균 그라디언트로 한 번씩 업데이트. 방향은 안정적이지만 너무 “신중”하고, 로컬 미니멈에 잘 갇힘.
미니배치 SGD는 배치 크기를 1<B<N으로 두고,
- 매 스텝마다 데이터 B개를 뽑아(예: 주머니에서 여러 개 꺼내듯이)
- 그 B개의 로스를 평균낸 뒤 그라디언트를 계산하여 업데이트하는 방식입니다.
배치 크기 B를 키울수록, 그라디언트가 더 “배치 GD스럽게” 안정해지고, B를 줄일수록 “SGD스럽게” 노이즈가 커집니다.
왜 배치 크기를 무작정 키우면 안 되는가?
GPU 병렬 연산 덕분에, 여러 샘플을 동시에 처리하면 한 스텝 계산 시간은 거의 일정한데, 한 스텝당 쓰는 샘플 수는 늘릴 수 있습니다.
그래서 겉으로 보기에는 “배치 크기를 크게 할수록 더 효율적”처럼 보이지만, 실험·이론 결과 배치 크기가 너무 크면 다음 문제가 나타납니다.
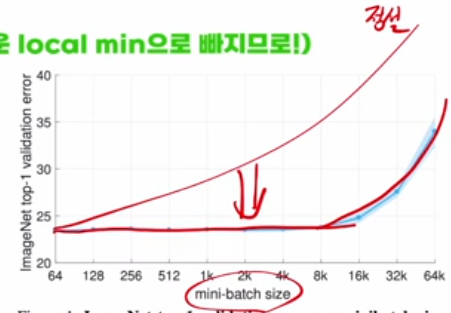
- 일반화 오류 증가: 어느 정도까지는 배치 크기를 늘려도 성능이 유지되지만, 임계점(영상에서 예시로 든 8k 근처)을 지나면 검증 에러가 다시 커지는 경향이 관찰됩니다.
- 탐색 성질 악화: 배치가 커질수록 그라디언트가 거의 “정확한 평균”이 되어 로컬 미니멈 주변에서 노이즈가 줄어들고, SGD가 갖던 “노이즈로 웅덩이를 탈출하는” 성질이 약해집니다. 그 결과, 초기 가중치 근처의 로컬 미니멈에 더 쉽게 갇히는 쪽, 즉 배치 GD와 비슷한 성질을 띠게 됩니다.
요약하면, 큰 배치는
- 계산 효율은 좋지만
- 최적화·일반화 관점에서는 반드시 좋은 것만은 아니고, 어느 지점부터는 오히려 해가 될 수 있다는 것이 강의의 메시지입니다.
큰 배치에서 쓰는 두 가지 보정: LR 스케일링과 웜업
강의에서 소개하는 유명한 논문(대형 배치로 ImageNet 학습) 아이디어는 크게 두 가지입니다.
1. 배치 두 배 → 러닝레이트도 두 배 (Linear Scaling Rule)
- 배치 크기를 B B에서 2 B 2B로 두 배로 키우면, 한 스텝에서 보는 샘플 수가 두 배가 되므로,
- “같은 양의 데이터에 대해 비슷한 파라미터 변화량”을 얻으려면 러닝레이트 α α도 두 배로 키우는 것이 합리적이라는 해석입니다.
- 수식으로 보면, MSE 기반 로스에서 배치 평균 그라디언트 앞에 1 B B 1 가 붙기 때문에, B B가 커질수록 동일한 스텝 길이를 유지하려면 α α를 같이 키워야 한다는 논리입니다.



2. 러닝레이트 웜업(warm-up)
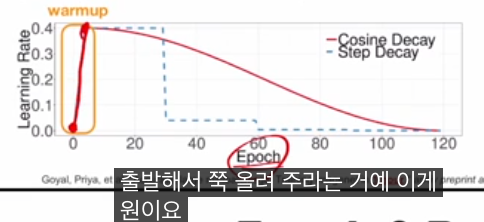

- 초기에는 가중치가 불안정하고 그라디언트 값도 들쭉날쭉하므로, 큰 α α를 처음부터 쓰면 발산·불안정이 발생할 수 있습니다.
- 그래서 처음 몇 에폭(또는 스텝) 동안은 작은 러닝레이트에서 시작해 서서히 목표 값까지 올린 뒤, 그 이후에는 일정하게 유지하거나 코사인, 스텝 디케이 등으로 줄여 나가는 스케줄을 사용합니다.

이 두 아이디어를 함께 쓰면, 상당히 큰 배치에서도 어느 정도 좋은 성능을 유지할 수 있지만, 그래도 너무 큰 배치 영역에서는 여전히 에러가 상승하는 구간이 남는다는 점을 강의에서 강조합니다.
에폭, 배치 사이즈, 하이퍼파라미터 정리
마지막으로 강의는 학습 관련 용어와 하이퍼파라미터를 정리합니다.

- 에폭(epoch): 전체 데이터를 몇 번 반복해서 볼 것인지.
-- 주머니 비유에서 “주머니에 있는 데이터를 다 꺼내서 한 번씩 쓴 뒤 다시 넣는 과정” 한 사이클이 에폭 1.
- 배치 사이즈(batch size): 한 번의 업데이트에 몇 개 샘플을 사용할지.

- 파라미터(parameter): 모델이 학습으로 스스로 찾는 값들 (가중치, 바이어스 등).
- 하이퍼파라미터(hyperparameter): 사람이 정해 줘야 하는 값들.
-- 에폭 수, 배치 사이즈, 초기 학습률, 학습률 스케줄링, 초기화 방식, 레이어/노드 수, 활성함수, 옵티마이저 종류, 로스 함수 등.
실전에서는 이 하이퍼파라미터들을 여러 조합으로 바꿔가며, 계산 자원·시간·성능(일반화) 사이에서 균형 잡힌 지점을 찾는 것이 중요하다는 메시지로 마무리합니다.
[Easy! 딥러닝] 3-4강. momentum 쉬운 설명 | 치타만 기억하세요!
이 3-4강의 핵심은 “모멘텀(momentum)은 과거 그라디언트를 누적해서 ‘관성’을 주어, 좁고 긴 골짜기에서 좌우로 심하게 흔들리지 않고 앞으로 쭉 미끄러지듯 빠르게 내려가게 만드는 방법”이라는 점입니다.

왜 모멘텀이 필요한가
미니배치 SGD만 사용하면, 로스 지형이 타원형(좁고 긴 골짜기)일 때 그라디언트가 등고선의 법
선 방향으로 계속 바뀌기 때문에,
- 좌우로 크게 왔다 갔다(oscillation) 하면서
- 실제로 바닥 방향으로는 아주 조금씩만 전진하는 비효율적인 움직임이 생깁니다.
등고선의 접선에 수직한 방향이 그라디언트 방향이기 때문에, 골짜기가 길게 늘어진 방향보다는 “가장 급경사인 방향(옆 벽)”으로 계속 튀어서 이런 지그재그가 심해집니다.


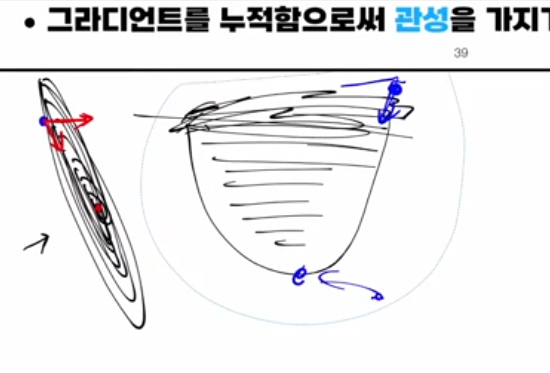



모멘텀의 아이디어: ‘관성’을 가진 치타
모멘텀은 “현재 그라디언트만 보지 말고, 이전 스텝들에서 이동해 온 방향도 함께 고려해서 관성을 주자”는 아이디어입니다.
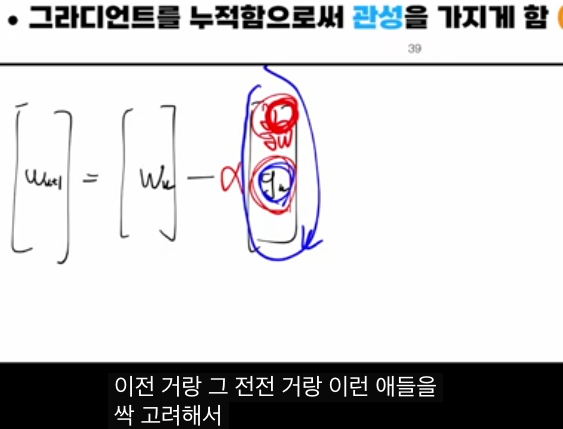
전형적인 수식 형태는 다음과 같습니다.
- 속도(또는 모멘텀) 업데이트:

- 파라미터 업데이트:

여기서
- β는 모멘텀 계수(보통 0.9 근처),
- vk 는 이전까지의 그라디언트가 누적된 “속도”,
- α는 러닝 레이트입니다.
이렇게 하면
- 좌·우로 그라디언트 방향이 자주 바뀌는 축에서는 과거의 이동들이 서로 상쇄되어 진동이 줄고,
- 앞쪽(골짜기 바닥 방향)으로는 같은 부호의 그라디언트가 계속 누적되어 점점 더 큰 보폭으로 빠르게 내려가게 됩니다.
강의의 치타 비유처럼, 방향이 갑자기 꺾여도 몸이 한쪽으로 계속 쏠려 있는 관성 때문에 완전히 급격하게 꺾이지 못하고, 큰 흐름 방향을 유지하면서 조금씩 꺾여 가는 그림을 떠올리면 됩니다.
효과 정리
모멘텀을 추가한 GD/SGD는 다음과 같은 장점을 가집니다.
- 좁고 긴 골짜기에서 좌우 진동을 줄이고 수렴을 빠르게 함.
- 그라디언트가 일관된 방향으로 계속 나오는 축에서는 보폭을 키워 학습을 가속.
- 그 과정에서 작은 로컬 미니멈이나 새들 포인트를 관성으로 넘어설 가능성도 커집니다.
영상의 요지는 “모멘텀 = 과거 그라디언트의 누적(관성)으로, 좌우로 흔들리는 에너지는 상쇄하고, 앞으로 가는 에너지는 키워 주는 최적화 트릭”이라고 이해하면 된다는 것입니다.
[Easy! 딥러닝] 3-5강. RMSProp 수식 없이 설명하기
3-5강에서는 “RMSProp은 각 파라미터 방향마다 최근 그라디언트 크기를 따로 추적해서, 가파른 방향은 조심조심, 완만한 방향은 과감하게 가도록 ‘축별 러닝레이트’를 자동으로 조정하는 옵티마이저”라는 직관을 주려고 합니다.

핵심 아이디어: 축마다 다른 학습률
예시로 그라디언트가

(g a ,g b )=(0.1,10)처럼 한 축(a)은 작고 다른 축(b)은 큰 경우를 듭니다. 단순 GD라면 두 축에 같은 러닝레이트 α를 곱하니, 사실상 b축으로만 크게 움직이고 a축으로는 거의 안 움직여 최적점을 향한 균형 이동이 어려워집니다.
RMSProp은 각 파라미터에 대해 최근 제곱 그라디언트의 이동평균을 추적한 뒤,
- 그 값이 큰 방향(항상 그라디언트가 큰, 가파른 방향)은 “위험하니” 스텝을 줄이고
- 값이 작은 방향(완만하거나 평평한 방향)은 “과감히 더 멀리” 가게 합니다.
수식 관점에서는 “각 파라미터별 러닝레이트를, 최근 그라디언트 제곱의 제곱근으로 나눈 값으로 스케일한다”라고 볼 수 있습니다.
평탄·급경사 구간에서의 동작 직관

강의에서 말하듯이,
- 그라디언트가 큰 축 = 로스가 가파르게 떨어지는 방향 → 너무 빨리 움직이면 깊은 웅덩이에 빠질 위험이 있어 스텝을 줄입니다.
- 그라디언트가 작은 축 = 로스가 완만하거나 거의 평평한 방향(plateau) → 어디로 조금 가도 로스 변화가 작으니, 이런 데서는 스텝을 키워 빨리 벗어나게 합니다.
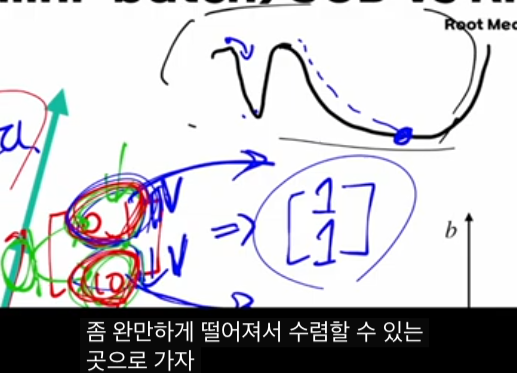
그래서 RMSProp은
- 좁고 깊게 파인 방향(가파른 골짜기, 이상한 웅덩이)에서는 “브레이크를 잡듯” 조심스럽게,
- 넓고 평탄한 구간에서는 “가속 페달을 밟듯” 빠르게 움직이며,
그 결과 단순 SGD보다 plateau 탈출과 수렴 속도가 좋아지는 경향이 있습니다.
모멘텀과의 관계, Adam으로의 연결
모멘텀은 “방향(1차 모멘트)을 누적해 관성을 주는 방법”이었다면, RMSProp은 “크기(제곱, 2차 모멘트)를 누적해 축별 스케일을 조절하는 방법”입니다.
영상 마지막에서 언급하듯, Adam은 이 두 가지(모멘텀 + RMSProp 스타일의 적응 학습률)를 합친 Adaptive Moment Estimation 이고, 다음 강의에서 이어질 내용의 준비 단계로 RMSProp을 소개하는 구조입니다.
[Easy! 딥러닝] 3-6강. Adam (Adaptive Moment Estimation) 완벽 정리!
3-6강의 핵심은 “Adam(Adaptive Moment Estimation)은 모멘텀 + RMSProp을 동시에 쓰는 옵티마이저라서, 방향(평균 그래디언트)과 크기(그래디언트 제곱)를 모두 누적해 각 파라미터별로 ‘관성도 있고, 적응 학습률도 있는’ 업데이트를 해 준다”는 점입니다.

Adam 수식의 구조와 의미
강의에서 Adam 업데이트를 한 줄로 요약하면 다음 형태입니다.
- 1차 모멘트(평균, 모멘텀 역할): 과거 그래디언트를 지수이동평균으로 누적 → m t .
- 2차 모멘트(분산, RMSProp 역할): 그래디언트 제곱의 지수이동평균을 누적 → v t .
- 파라미터 업데이트:
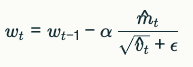
여기서 m ^ t , v ^ t m ^ t , v ^ t 는 “초기 0에서 시작해서 값이 작게 나오는 편향(bias)을 보정한 버전”입니다.
강의에서는 직관을 위해 β 1 ,β 2 를 1에 가깝게 두고, m t 는 과거 그래디언트를 점점 덜 가중해 누적하는 지수 이동 평균(Exponential Moving Average), v t 는 그래디언트 크기(제곱)의 지수 이동 평균이라는 점을 손으로 풀어 보여 줍니다.
모멘텀 + RMSProp가 동시에 들어가는 방식
Adam은 다음 두 가지 효과를 동시에 냅니다.
- 분자 m t :
-- 과거 그래디언트를 방향 정보로 누적 → 모멘텀처럼 관성을 만들어, 골짜기에서 한 방향으로 더 안정적으로, 빠르게 이동.
- 분모 (루트)v t +ϵ:

-- 최근 그래디언트 제곱을 누적한 값으로 스케일링 → RMSProp처럼 적응 학습률을 만들어,
--- 자주 크고 가파른 방향(많이 탐색한 축)은 스텝을 줄이고
--- 거의 변화가 없는 평탄한 방향(덜 탐색한 축)은 스텝을 키워 줌.
여기에 아주 작은 ϵ을 더해 분모가 0에 가까워질 때 “뿅 튀는” 것을 막고, 평탄 영역에서 너무 과도한 점프를 방지하는 안전장치 역할을 합니다.




편향 보정과 실제 장·단점
지수이동평균을 0에서 시작하면 초기 몇 스텝 동안 m t ,v t 가 실제보다 지나치게 작게 잡히는 편향이 생기므로, 논문에서는 이를 나누어 주는 형태의 bias correction 항을 넣어 보정합니다. 강의에서 말하듯 이 보정은 “초반에 EMA가 0에서 출발하는 문제를 바로잡아, 평균이 더 제대로 된 값에 빨리 수렴하도록 하는 역할”입니다.
실무 관점에서 Adam은
- 수렴이 빠르고,
- 스케일·초기값·평탄/가파른 영역에 꽤 강건해서
딥러닝에서 “좋은 디폴트 옵티마이저”로 널리 쓰입니다. 다만, SGD(+모멘텀)에 비해 항상 일반화가 더 좋은 것은 아니라는 연구도 있고, 최근에는 문제 특성에 따라 Adam, AdamW, SGD 등을 골라 쓰는 흐름입니다.








[AI 인공지능 머신러닝 딥러닝] - 이지 딥러닝 - 혁펜하임 | Easy! 딥러닝 4강 Train · Validation · Test, K-fold
이지 딥러닝 - 혁펜하임 | Easy! 딥러닝 4강 Train · Validation · Test, K-fold
[AI 인공지능 머신러닝 딥러닝] - 이지 딥러닝 - 혁펜하임 | Easy! 딥러닝 - 무료 강의 및 책 소개 이지 딥러닝 - 혁펜하임 | Easy! 딥러닝 - 무료 강의 및 책 소개한국어로 딥러닝 공부해봤다는 사람중
inner-game.tistory.com