Julia 프로그래밍 - 머신 러닝을 위한 Julia
[AI 인공지능 머신러닝 딥러닝/Julia] - Julia 프로그래밍 - 언어 및 강의 소개
Julia 프로그래밍 - 언어 및 강의 소개
Julia 프로그래밍 언어줄리아(Julia)는 고성능의 수치 해석 및 계산과학의 필요 사항을 만족시키면서 일반 목적 프로그래밍에도 효과적으로 사용될 수 있도록 설계된 고급 동적 프로그래밍 언어이
inner-game.tistory.com
[AI 인공지능 머신러닝 딥러닝/Julia] - Julia 프로그래밍 - Julia 설치
Julia 프로그래밍 - Julia 설치
이전 글[AI 인공지능 머신러닝 딥러닝/Julia] - Julia 프로그래밍 - 언어 및 강의 소개 Julia 프로그래밍 - 언어 및 강의 소개Julia 프로그래밍 언어줄리아(Julia)는 고성능의 수치 해석 및 계산과학의 필
inner-game.tistory.com
[AI 인공지능 머신러닝 딥러닝/Julia] - Julia 프로그래밍 - 사전, 세트 및 사용자 정의 유형
Julia 프로그래밍 - 사전, 세트 및 사용자 정의 유형
[AI 인공지능 머신러닝 딥러닝/Julia] - Julia 프로그래밍 - 언어 및 강의 소개 Julia 프로그래밍 - 언어 및 강의 소개Julia 프로그래밍 언어줄리아(Julia)는 고성능의 수치 해석 및 계산과학의 필요 사항
inner-game.tistory.com

MLJ.jl
데이터 세트 로딩
DataFrame 호환성
모델 선택
예 1: 분류
모델 로딩
모델 피팅
검사 결과
추론
평가
예제 2: PCA
추가 자료
MLJ.jl
using MLJ
이 강의는 MLJ (Julia의 머신 러닝) 에 대한 매우 간단한 설명입니다 .
다양한 플로팅 백엔드에 공통 인터페이스를 제공하는 Plots.jl과 유사하게 MLJ는 Julia 생태계의 많은 머신 러닝 패키지에 공통 인터페이스를 제공합니다.
함수를 사용하면 models사용 가능한 모든 머신 러닝 모델을 인쇄할 수 있습니다.

models() # click on the arrow ▶ above this cell to unfold the list
사용 가능한 모델 목록은 온라인에서도 확인할 수 있습니다.
데이터 세트 로딩
이 데모의 목적을 위해, 우리는 MLJ에 내장된 데이터 세트 중 하나인 아이리스 꽃 데이터 세트를 사용할 것입니다 .
이 다변량 데이터세트는 붓꽃 세 종( setosa , versicolor , virginica) 에서 채취한 150개의 샘플을 포함합니다 . 각 꽃의 네 가지 특징, 즉 꽃잎 길이와 너비, 꽃받침 길이와 너비가 측정됩니다.

data = load_iris()
DataFrame 호환성
MLJ는 DataFrames.jl과 호환되므로 Pluto Notebook 내부의 데이터를 탐색할 수 있습니다.
using DataFrames

iris = DataFrame(data)
아이리스 꽃 데이터 세트 Wikipedia 문서는 훌륭한 시각화를 제공합니다.

*( Wikipedia 사용자 Nicoguaro의 CC BY 4.0 라이선스에 따라 사용됨 )*
모델 선택
우리의 목표 변수인 꽃의 종은 적절하게도 라고 불립니다 target. 를 사용하여 unpack데이터를 특징점과 목표로 나눌 수 있습니다. 선택적인 rng매개변수는 데이터를 재현 가능하게 섞습니다.
y, X = unpack(iris, ==(:target); rng=123);
이전에는 이 함수를 사용하여 modelsMJL에서 사용 가능한 모든 모델을 출력했습니다. 이제 데이터를 로드했으므로 모델을 필터링하여 사용 가능한 모델만 볼 수 있습니다.
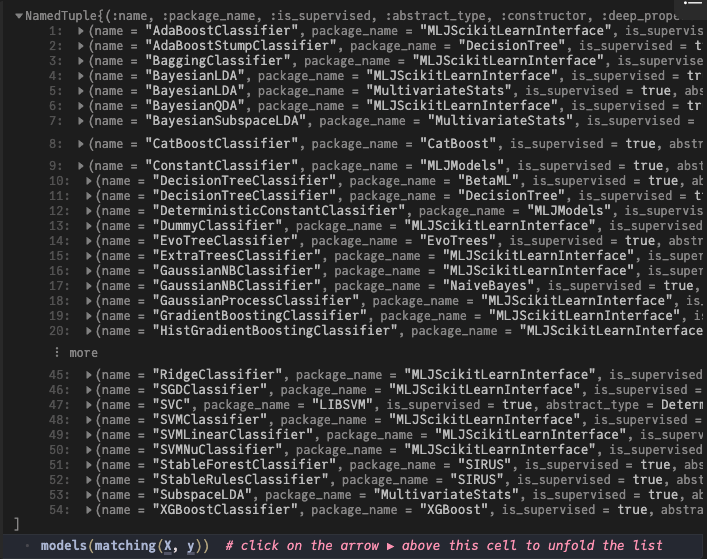
models(matching(X, y)) # click on the arrow ▶ above this cell to unfold the list
예 1: 분류
모델 로딩
DecisionTreeClassifier패키지 에서 를 로드해 보겠습니다 DecisionTree.
대화형 세션에서는 MLJ의 대화형 로딩 기능을 실행하기만 하면 됩니다.@iload
DecisionTreeClassifier =@iload DecisionTreeClassifier
설치 과정을 안내해 드립니다. 앞서 언급했듯이 MLJ는 Julia 생태계의 다른 머신 러닝 패키지를 감싸는 대형 래퍼 패키지입니다. MLJ는 필요할 때만 필수 패키지를 설치합니다.
설치 과정에서는 MLJDecisionTreeInterface.jl을DecisionTreeClassifier 설치하고 패키지 BetaML.jl 에서 내보낸 것을 사용할지 , 아니면 DecisionTree.jl 에서 내보낸 것을 사용할지 묻습니다 .

Pluto 노트북에서는 다음 명령을 수동으로 실행해야 합니다.
using MLJDecisionTreeInterface
DecisionTreeClassifier = @load DecisionTreeClassifier pkg = "DecisionTree" verbosity = false;
이제 모델을 인스턴스화할 수 있습니다. 이 예에서는 기본 하이퍼파라미터를 사용합니다.
model
DecisionTreeClassifier(
max_depth = -1,
min_samples_leaf = 1,
min_samples_split = 2,
min_purity_increase = 0.0,
n_subfeatures = 0,
post_prune = false,
merge_purity_threshold = 1.0,
display_depth = 5,
feature_importance = :impurity,
rng = Random._GLOBAL_RNG())
model = DecisionTreeClassifier()
모델 피팅
데이터 분할
먼저 데이터를 70:30으로 나누어 훈련 세트와 테스트 세트로 정의해 보겠습니다.

train, test = partition(eachindex(y), 0.7)
기계
MLJ는 '머신' 이라는 개념을 적극적으로 활용합니다 . 머신은 모델을 데이터에 연결하고 학습된 매개변수를 저장합니다.
DecisionTreeClassifier를 iris 데이터셋에 바인딩해 보겠습니다 . 그런 다음 fit!머신을 호출하여 데이터에 맞춰 학습할 수 있습니다.
trained Machine; caches model-specific representations of data
model: DecisionTreeClassifier(max_depth = -1, …)
args:
1: Source @256 ⏎ ScientificTypesBase.Table{AbstractVector{ScientificTypesBase.Continuous}}
2: Source @062 ⏎ AbstractVector{ScientificTypesBase.Multiclass{3}}
begin
mach = machine(model, X, y) # define machine: binds model to data
mach = fit!(mach; rows=train) # fit model on train set
end
Training machine(DecisionTreeClassifier(max_depth = -1, …), …).
검사 결과
fitted_params머신을 호출하면 학습된 모든 매개변수가 반환됩니다.
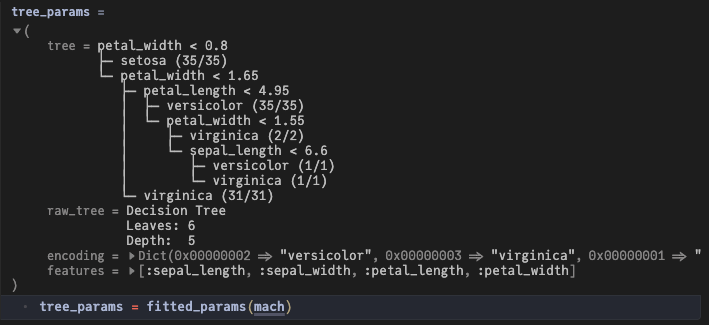
tree_params = fitted_params(mach)
우리 모델의 경우, 우리는 주로 학습된 의사결정 트리에 관심이 있습니다.
petal_width < 0.8
├─ setosa (35/35)
└─ petal_width < 1.65
├─ petal_length < 4.95
│ ├─ versicolor (35/35)
│ └─ petal_width < 1.55
│ ├─ virginica (2/2)
│ └─ sepal_length < 6.6
│ ├─ versicolor (1/1)
│ └─ virginica (1/1)
└─ virginica (31/31)tree_params.tree
이 트리의 가지는 if-else 문으로 읽을 수 있습니다. 위 데이터셋의 플롯과 비교해 보세요!
추론
훈련된 머신을 사용하여 mach세 개의 새로운 데이터 포인트를 예측해 보겠습니다.
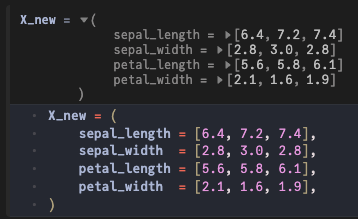
X_new = (
sepal_length = [6.4, 7.2, 7.4],
sepal_width = [2.8, 3.0, 2.8],
petal_length = [5.6, 5.8, 6.1],
petal_width = [2.1, 1.6, 1.9],
)
우리는 확률적 예측을 얻을 수 있습니다
CategoricalDistributions.UnivariateFiniteVector{ScientificTypesBase.Multiclass{3}, String, UInt32, Float64}:
UnivariateFinite{ScientificTypesBase.Multiclass{3}}(setosa=>0.0, versicolor=>0.0, virginica=>1.0)
UnivariateFinite{ScientificTypesBase.Multiclass{3}}(setosa=>0.0, versicolor=>0.0, virginica=>1.0)
UnivariateFinite{ScientificTypesBase.Multiclass{3}}(setosa=>0.0, versicolor=>0.0, virginica=>1.0)
predict(mach, X_new)
또는 지점 예측:
CategoricalArrays.CategoricalVector{String, UInt32, String, CategoricalArrays.CategoricalValue{String, UInt32}, Union{}}:
"virginica"
"virginica"
"virginica"
predict_mode(mach, X_new)
평가
테스트 세트에서 훈련된 분류기를 평가해 보겠습니다.

ŷ_test = predict(mach, X[test, :])y_test = y[test];
MLJ는 다음을 실행하여 인쇄할 수 있는 많은 손실 및 점수 함수를 제공합니다 measures().

measures() # click on the arrow ▶ above this cell to unfold the list
*평균 교차 엔트로피 손실 ( 로그 손실* 이라고도 함 )을 평가해 보겠습니다 .
1.6019401506274291
mean(cross_entropy(ŷ_test, y_test))
예제 2: PCA
두 번째 예를 빠르게 살펴보고 Iris 데이터 세트에 PCA (주성분 분석) 를 적용해 보겠습니다 .
begin
# Load required packages
using MLJMultivariateStatsInterface
PCA = @load PCA verbosity = false
# Define and fit machine
pca = PCA(; maxoutdim=2)
mach2 = machine(pca, X)
fit!(mach2)
# Return learned parameters / projection
pca_params = fitted_params(mach2)
end;Training machine(PCA(maxoutdim = 2, …), …).
이는 데이터를 더 낮은 차원의 공간으로 투영하는 것을 계산합니다.
4×2 Matrix{Float64}: -0.36159 0.65654 0.0822689 0.729712 -0.856572 -0.175767 -0.358844 -0.0747065
pca_params.projection
추가 자료
이 강의는 MLJ의 기능 중 극히 일부만 다루었습니다. 예를 들어, 다음 기능은 다루지 않았습니다.
자세한 내용은 MLJ 문서 에서 확인할 수 있습니다 .
위의 대체 링크: https://juliaai.github.io/MLJ.jl/stable/