Design - Top Interview Questions[Medium] (7/9) : Python
Design
These problems may require you to implement a given interface of a class, and may involve using one or more data structures. These are great exercises to improve your data structure skills.
We recommend: Serialize and Deserialize Binary Tree and Insert Delete GetRandom O(1)
Flatten 2D Vector
Serialize and Deserialize Binary Tree
Insert Delete GetRandom O(1)
Design Tic-Tac-Toe
251. Flatten 2D Vector
leetcode.com/problems/flatten-2d-vector/
Medium
405236Add to ListShare
Design and implement an iterator to flatten a 2d vector. It should support the following operations: next and hasNext.
Example:
Vector2D iterator = new Vector2D([[1,2],[3],[4]]); iterator.next(); // return 1 iterator.next(); // return 2 iterator.next(); // return 3 iterator.hasNext(); // return true iterator.hasNext(); // return true iterator.next(); // return 4 iterator.hasNext(); // return false
Notes:
- Please remember to RESET your class variables declared in Vector2D, as static/class variables are persisted across multiple test cases. Please see here for more details.
- You may assume that next() call will always be valid, that is, there will be at least a next element in the 2d vector when next() is called.
Follow up:
As an added challenge, try to code it using only iterators in C++ or iterators in Java.
How many variables do you need to keep track?
Hide Hint 2
Two variables is all you need. Try with x and y.
Hide Hint 3
Beware of empty rows. It could be the first few rows.
Hide Hint 4
To write correct code, think about the invariant to maintain. What is it?
Hide Hint 5
The invariant is x and y must always point to a valid point in the 2d vector. Should you maintain your invariant ahead of time or right when you need it?
Hide Hint 6
Not sure? Think about how you would implement hasNext(). Which is more complex?
Hide Hint 7
Common logic in two different places should be refactored into a common method.
Solution
Overview
This question should be fairly straightforward if you're familiar with what an Iterator is. If you aren't at all familiar with Iterators though, then we suggest having a go at Peeking Iterator. Additionally, the Solution Article for Peeking Iterator has a special introduction section that introduces you to what Iterators are.
Note that this question refers to something called a Vector. A Vector is simply another name for Array. To be consistent with the question, we've chosen to use the term Vector, rather than Array for this article (Sorry in advance for any confusion this causes, C++ programmers).
Approach 1: Flatten List in Constructor
Intuition
This approach is a bad approach! We've included it though, to show what it looks like, and to discuss why it's bad. This will help you to design good Iterators.
In the constructor, we can iterate over the 2D input vector, putting each integer into a List. Then, the problem simplifies to being a simple List Iterator. Note that the reason we use a List rather than an array (vector) is because we don't know in advance how many integers there might be in total.
Our unpack algorithm would be as follows.
nums = a new List for each innerVector in the input 2D Vector: for each number in innerVector: append number to the end of nums
We'll then need to save this List as a field of our Iterator class, seeing as the next(...) and hasNext(...) methods will need to access it repeatedly. By then also having a position field, we can keep track of where the Iterator is up to.
Algorithm
The code shown here makes the position field point at the next element that needs to be returned by next. Therefore, the hasNext() method simply needs to check that position is a valid index of nums. A similar variant would be to make position point at the previous value that was returned. This would simplify the next() method, but complicate the hasNext() method.
Complexity Analysis
Let NN be the number of integers within the 2D Vector, and VV be the number of inner vectors.
-
Time complexity.
-
Constructor: O(N + V)O(N+V).
In total, we'll append NN integers to the nums list. Each of these appends is an O(1)O(1) operation. This gives us O(N)O(N).
Something to be cautious of is that inner vectors don't have to contain integers. Think of a test cases such as [[], [2], [], [], []]. For this test case, N = 1N=1, because there's only one integer within it. However, the algorithm has to loop through all of the empty vectors. The cost of checking all the vectors is O(V)O(V).
Therefore, we get a final time complexity of O(N + V)O(N+V).
-
next(): O(1)O(1).
All operations in this method, including getting the integer at a specific index of a list, are O(1)O(1).
-
hasNext(): O(1)O(1).
All operations in this method are O(1)O(1).
-
-
Space complexity : O(N)O(N).
We're making a new list that contains all of the integers from the 2D Vector. Notice that this is different from the time complexity; in the example of [[], [2], [], [], []], we only store the 2. All information about how many inner vectors there were is discarded.
Why is this implementation bad?
This code works, it runs fast here on Leetcode, it seems pretty straightforward to implement.
However, one of the main purposes of an Iterator is to minimize the use of auxiliary space. We should try to utilize the existing data structure as much as possible, only adding as much extra space as needed to keep track of the next value. In some situations, the data structure we want to iterate over is too large to even fit in memory anyway (think of file systems).
In the case of our above implementation, we might as well have just had a single function List<Integer> getFlattenedVector(int[][] v), which would return a List of integers, that could then be iterated over using the List types own standard Iterator.
As a general rule, you should be very cautious of implementing Iterators with a high time complexity in the constructor, with a very low time complexity in the next() and hasNext() methods. If the code using the Iterator only wanted to access the first couple of elements in the iterated collection, then a lot of time (and probably space) has been wasted!
As a side note, modifying the input collection in any way is bad design too. Iterators are only allowed to look at, not change, the collection they've been asked to iterate over.
Approach 2: Two Pointers
Intuition
Like we said above, Approach 1 is bad because it creates a new data structure instead of simply iterating over the given one. Instead, we should find a way to step through the integers one-by-one, keeping track of where we currently are in the 2D vector. The location of each number is represented with 2 indexes; the index of the inner vector, and the index of the integer within its inner vector. Here's an example 2D vector, with the indexes marked on it.

Suppose we are at the following position:

How do we find the next position? Well the current integer has another integer after it, within the same inner vector. Therefore, we can just increment inner index by 1. This gives the next position as shown below.
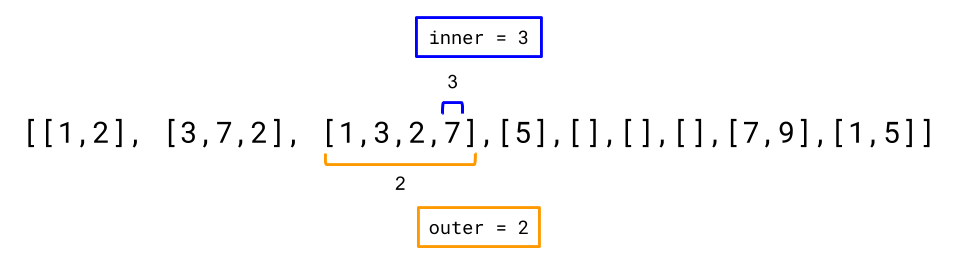
Now inner is at the end of the current inner vector. In order to get to the next integer we'll need to increment outer by 1, and set inner to 0 (as 0 is first index of the new vector).
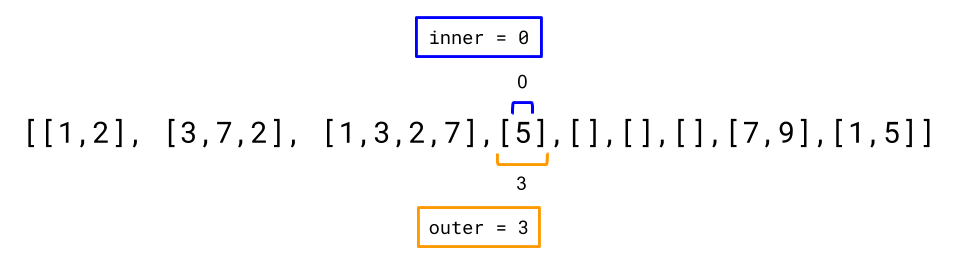
This time, it's a bit trickier, because we need to skip over empty vectors. To do that we repeatedly increment outer until we find an inner vector that is not empty (programmatically, this would be an outer where inner = 0 is valid). Once we find one, we stop and set inner to 0 (the first integer of the inner vector).

Note that when outer becomes equal to the length of the 2D vector, this means there are no more inner vectors and so there are no more numbers left.
Algorithm
In Approach 1, we used O(N)O(N) auxiliary space and O(N + V)O(N+V) time in the constructor. In this approach though, we perform the necessary work incrementally during calls to hasNext() and next(). This means that if the caller stops using the iterator before it's exhausted, we won't have done any unnecessary work.
We'll define an advanceToNext() helper method that checks if the current inner and outer values point to an integer, and if they don't, then it moves them forward until they point to an integer (in the way described above). If outer == vector.length becomes true, then the method terminates (because there's no integers left).
In order to ensure no unnecessary work is done, the constructor doesn't check whether or not vector[0][0] points to an integer. This is because there might be an arbitrary number of empty inner vectors at the start of the input vector; potentially costing up to O(V)O(V) operations to skip past.
Both hasNext() and next() start by calling advanceToNext() to ensure that inner and outer point to an integer, or that outer is at its "stop" value of outer = vector.length.
next() returns the integer at vector[inner][outer], and then increments inner by 1, so that the next call to advanceToNext() will start searching from after the integer we've just returned.
It is important to note that calling the hasNext() method will only cause the pointers to move if they don't point to an integer. Once they point to an integer, repeated calls to hasNext() will not move them further. Only next() is able to move them off a valid integer. This design ensures that the client code calling hasNext() multiple times will not have unusual side effects.
Complexity Analysis
Let NN be the number of integers within the 2D Vector, and VV be the number of inner vectors.
-
Time complexity.
-
Constructor: O(1)O(1).
We're only storing a reference to the input vector—an O(1)O(1) operation.
-
advanceToNext(): O(\dfrac{V}{N})O(NV).
If the iterator is completely exhausted, then all calls to advanceToNext() will have performed O(N + V)O(N+V) total operations. (Like in Approach 1, the VV comes from the fact that we go through all VV inner vectors, and the NN comes from the fact we perform one increment for each integer).
However, because we perform NN advanceToNext() operations in order to exhaust the iterator, the amortized cost of this operation is just \dfrac{O(N + V)}{N} = O(\dfrac{N}{N} + \dfrac{V}{N}) = O(\dfrac{V}{N})NO(N+V)=O(NN+NV)=O(NV).
-
next() / hasNext(): O(\dfrac{V}{N})O(NV) or O(1)O(1).
The cost of both these methods depends on how they are called. If we just got a value from next(), then the next call to either method will involve calling advanceToNext(). In this case the time complexity is O(\dfrac{V}{N})O(NV).
However if we call hasNext(), then all successive calls to hasNext(), or the next call to next(), will be O(1)O(1). This is because advanceToNext() will only perform an O(1)O(1) check and immediately return.
-
-
Space complexity : O(1)O(1).
We only use a fixed set of O(1)O(1) fields (remember vector is a reference, not a copy!). So the space complexity is O(1)O(1).
297. Serialize and Deserialize Binary Tree
leetcode.com/problems/serialize-and-deserialize-binary-tree/
Hard
3795180Add to ListShare
Serialization is the process of converting a data structure or object into a sequence of bits so that it can be stored in a file or memory buffer, or transmitted across a network connection link to be reconstructed later in the same or another computer environment.
Design an algorithm to serialize and deserialize a binary tree. There is no restriction on how your serialization/deserialization algorithm should work. You just need to ensure that a binary tree can be serialized to a string and this string can be deserialized to the original tree structure.
Clarification: The input/output format is the same as how LeetCode serializes a binary tree. You do not necessarily need to follow this format, so please be creative and come up with different approaches yourself.
Example 1:

Input: root = [1,2,3,null,null,4,5] Output: [1,2,3,null,null,4,5]
Example 2:
Input: root = [] Output: []
Example 3:
Input: root = [1] Output: [1]
Example 4:
Input: root = [1,2] Output: [1,2]
Constraints:
- The number of nodes in the tree is in the range [0, 104].
- -1000 <= Node.val <= 1000
Solution
Approach 1: Depth First Search (DFS)
Intuition

The serialization of a Binary Search Tree is essentially to encode its values and more importantly its structure. One can traverse the tree to accomplish the above task. And it is well know that we have two general strategies to do so:
-
Breadth First Search (BFS)
We scan through the tree level by level, following the order of height, from top to bottom. The nodes on higher level would be visited before the ones with lower levels.
-
Depth First Search (DFS)
In this strategy, we adopt the depth as the priority, so that one would start from a root and reach all the way down to certain leaf, and then back to root to reach another branch.
The DFS strategy can further be distinguished as preorder, inorder, and postorder depending on the relative order among the root node, left node and right node.
In this task, however, the DFS strategy is more adapted for our needs, since the linkage among the adjacent nodes is naturally encoded in the order, which is rather helpful for the later task of deserialization.
Therefore, in this solution, we demonstrate an example with the preorder DFS strategy. One can check out more tutorial about Binary Search Tree on the LeetCode Explore.
Algorithm
First of all, here is the definition of the TreeNode which we would use in the following implementation.
The preorder DFS traverse follows recursively the order of
root -> left subtree -> right subtree.
As an example, let's serialize the following tree. Note that serialization contains information about the node values as well as the information about the tree structure.
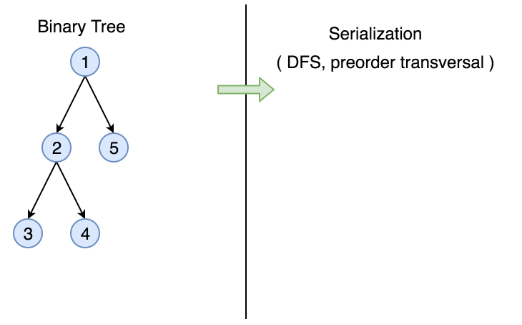
1 / 12
We start from the root, node 1, the serialization string is 1,. Then we jump to its left subtree with the root node 2, and the serialization string becomes 1,2,. Now starting from node 2, we visit its left node 3 (1,2,3,None,None,) and right node 4 (1,2,3,None,None,4,None,None) sequentially. Note that None,None, appears for each leaf to mark the absence of left and right child node, this is how we save the tree structure during the serialization. And finally, we get back to the root node 1 and visit its right subtree which happens to be a leaf node 5. Finally, the serialization string is done as 1,2,3,None,None,4,None,None,5,None,None,.
Now let's deserialize the serialization string constructed above 1,2,3,None,None,4,None,None,5,None,None,. It goes along the string, initiate the node value and then calls itself to construct its left and right child nodes.
Complexity Analysis
-
Time complexity : in both serialization and deserialization functions, we visit each node exactly once, thus the time complexity is O(N)O(N), where NN is the number of nodes, i.e. the size of tree.
-
Space complexity : in both serialization and deserialization functions, we keep the entire tree, either at the beginning or at the end, therefore, the space complexity is O(N)O(N).
The solutions with BFS or other DFS strategies normally will have the same time and space complexity.
Further Space Optimization
In the above solution, we store the node value and the references to None child nodes, which means N \cdot V + 2NN⋅V+2N complexity, where VV is the size of value. That is called natural serialization, and has was implemented above.
The N \cdot VN⋅V component here is the encoding of values, can't be optimized further, but there is a way to reduce 2N2N part which is the encoding of the tree structure.
The number of unique binary tree structures that can be constructed using n nodes is C(n)C(n), where C(n)C(n) is the nth Catalan number. Please refer to this article for more information.
There are C(n)C(n) possible structural configurations of a binary tree with n nodes, so the largest index value that we might need to store is C(n) - 1C(n)−1. That means storing the index value could require up to 1 bit for n \leq 2n≤2, or \lceil log_2(C(n) - 1) \rceil⌈log2(C(n)−1)⌉ bits for n > 2n>2.
In this way one could reduce the encoding of the tree structure by \log NlogN. More precisely, the Catalan numbers grow as C(n) \sim \frac{4^n}{n^{3/2}\sqrt{\pi}}C(n)∼n3/2π4n and hence the theoretical minimum of storage for the tree structure that could be achieved is log(C(n)) \sim 2n - \frac{3}{2}\log(n) - \frac{1}{2}\log(\pi)log(C(n))∼2n−23log(n)−21log(π)
380. Insert Delete GetRandom O(1)
leetcode.com/problems/insert-delete-getrandom-o1/
Medium
3109189Add to ListShare
Implement the RandomizedSet class:
- bool insert(int val) Inserts an item val into the set if not present. Returns true if the item was not present, false otherwise.
- bool remove(int val) Removes an item val from the set if present. Returns true if the item was present, false otherwise.
- int getRandom() Returns a random element from the current set of elements (it's guaranteed that at least one element exists when this method is called). Each element must have the same probability of being returned.
Follow up: Could you implement the functions of the class with each function works in average O(1) time?
Example 1:
Input ["RandomizedSet", "insert", "remove", "insert", "getRandom", "remove", "insert", "getRandom"] [[], [1], [2], [2], [], [1], [2], []] Output [null, true, false, true, 2, true, false, 2] Explanation RandomizedSet randomizedSet = new RandomizedSet(); randomizedSet.insert(1); // Inserts 1 to the set. Returns true as 1 was inserted successfully. randomizedSet.remove(2); // Returns false as 2 does not exist in the set. randomizedSet.insert(2); // Inserts 2 to the set, returns true. Set now contains [1,2]. randomizedSet.getRandom(); // getRandom() should return either 1 or 2 randomly. randomizedSet.remove(1); // Removes 1 from the set, returns true. Set now contains [2]. randomizedSet.insert(2); // 2 was already in the set, so return false. randomizedSet.getRandom(); // Since 2 is the only number in the set, getRandom() will always return 2.
Constraints:
- -231 <= val <= 231 - 1
- At most 105 calls will be made to insert, remove, and getRandom.
- There will be at least one element in the data structure when getRandom is called.
Solution
Overview
We're asked to implement the structure which provides the following operations in average \mathcal{O}(1)O(1) time:
-
Insert
-
Delete
-
GetRandom
First of all - why this weird combination? The structure looks quite theoretical, but it's widely used in popular statistical algorithms like Markov chain Monte Carlo and Metropolis–Hastings algorithm. These algorithms are for sampling from a probability distribution when it's difficult to compute the distribution itself.
Let's figure out how to implement such a structure. Starting from the Insert, we immediately have two good candidates with \mathcal{O}(1)O(1) average insert time:
-
Hashmap (or Hashset, the implementation is very similar): Java HashMap / Python dictionary
-
Array List: Java ArrayList / Python list
Let's consider them one by one.
Hashmap provides Insert and Delete in average constant time, although has problems with GetRandom.
The idea of GetRandom is to choose a random index and then to retrieve an element with that index. There is no indexes in hashmap, and hence to get true random value, one has first to convert hashmap keys in a list, that would take linear time. The solution here is to build a list of keys aside and to use this list to compute GetRandom in constant time.
Array List has indexes and could provide Insert and GetRandom in average constant time, though has problems with Delete.
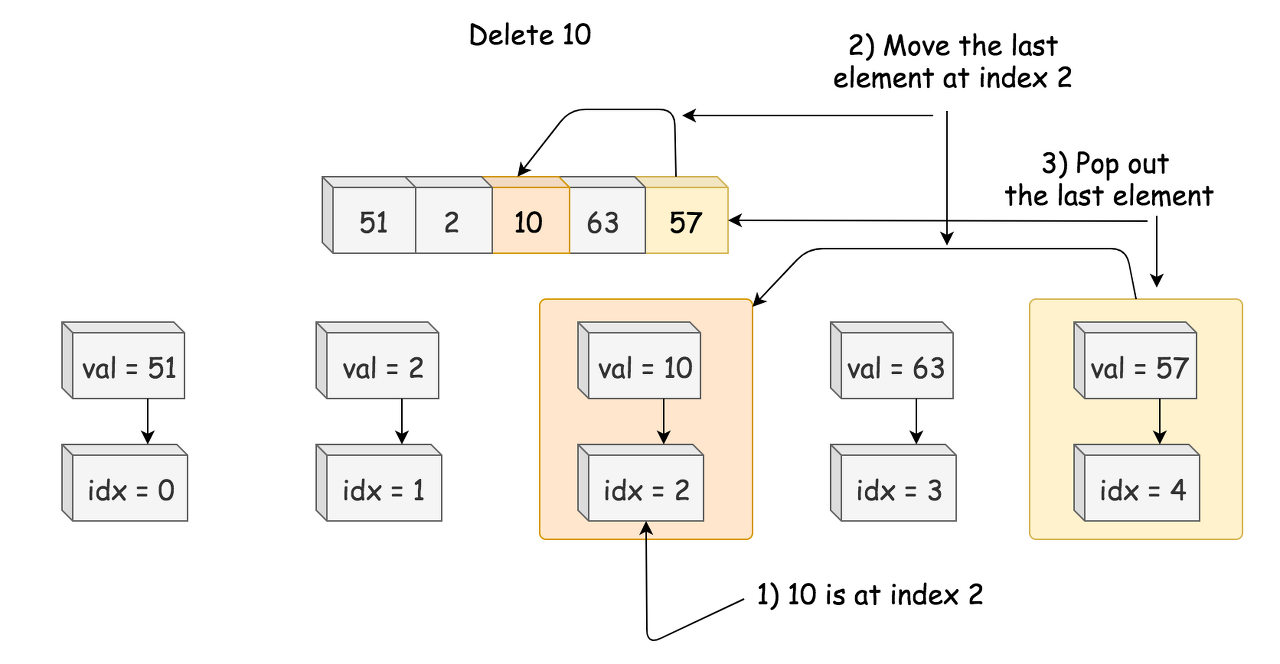
To delete a value at arbitrary index takes linear time. The solution here is to always delete the last value:
-
Swap the element to delete with the last one.
-
Pop the last element out.
For that, one has to compute an index of each element in constant time, and hence needs a hashmap which stores element -> its index dictionary.
Both ways converge into the same combination of data structures:
-
Hashmap element -> its index.
-
Array List of elements.
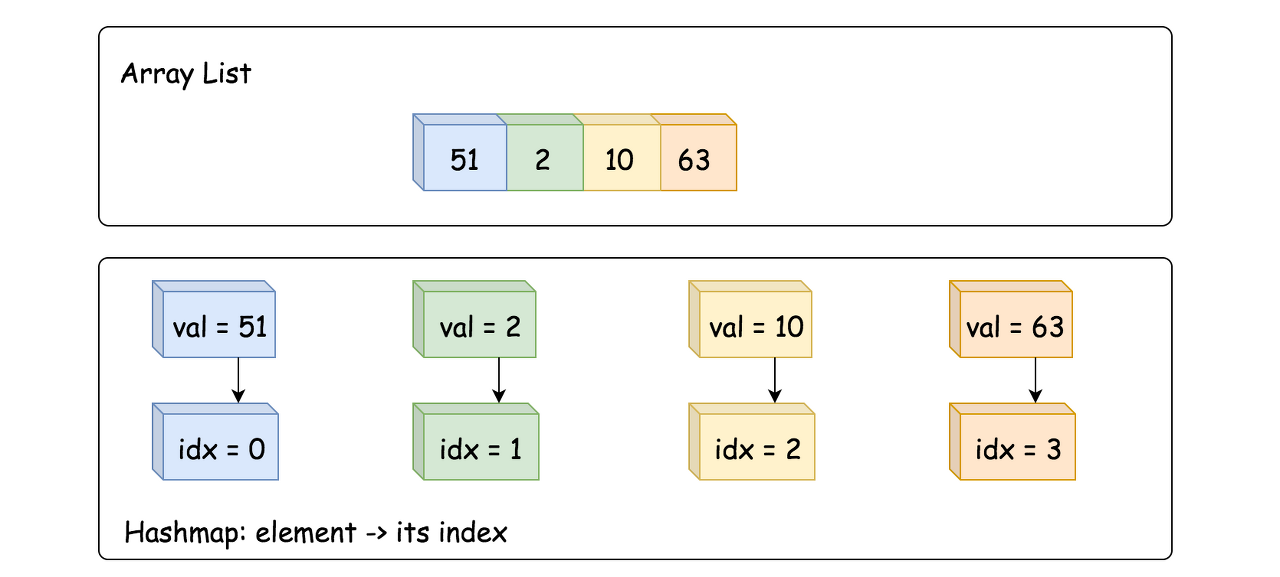
Approach 1: HashMap + ArrayList
Insert
-
Add value -> its index into dictionary, average \mathcal{O}(1)O(1) time.
-
Append value to array list, average \mathcal{O}(1)O(1) time as well.

Delete
-
Retrieve an index of element to delete from the hashmap.
-
Move the last element to the place of the element to delete, \mathcal{O}(1)O(1) time.
-
Pop the last element out, \mathcal{O}(1)O(1) time.
GetRandom
GetRandom could be implemented in \mathcal{O}(1)O(1) time with the help of standard random.choice in Python and Random object in Java.
Implementation
Complexity Analysis
-
Time complexity. GetRandom is always \mathcal{O}(1)O(1). Insert and Delete both have \mathcal{O}(1)O(1) average time complexity, and \mathcal{O}(N)O(N) in the worst-case scenario when the operation exceeds the capacity of currently allocated array/hashmap and invokes space reallocation.
-
Space complexity: \mathcal{O}(N)O(N), to store N elements.
348. Design Tic-Tac-Toe
leetcode.com/problems/design-tic-tac-toe/
Medium
94167Add to ListShare
Assume the following rules are for the tic-tac-toe game on an n x n board between two players:
- A move is guaranteed to be valid and is placed on an empty block.
- Once a winning condition is reached, no more moves are allowed.
- A player who succeeds in placing n of their marks in a horizontal, vertical, or diagonal row wins the game.
Implement the TicTacToe class:
- TicTacToe(int n) Initializes the object the size of the board n.
- int move(int row, int col, int player) Indicates that player with id player plays at the cell (row, col) of the board. The move is guaranteed to be a valid move.
Follow up:
Could you do better than O(n2) per move() operation?
Example 1:
Input ["TicTacToe", "move", "move", "move", "move", "move", "move", "move"] [[3], [0, 0, 1], [0, 2, 2], [2, 2, 1], [1, 1, 2], [2, 0, 1], [1, 0, 2], [2, 1, 1]] Output [null, 0, 0, 0, 0, 0, 0, 1] Explanation TicTacToe ticTacToe = new TicTacToe(3); Assume that player 1 is "X" and player 2 is "O" in the board. ticTacToe.move(0, 0, 1); // return 0 (no one wins) |X| | | | | | | // Player 1 makes a move at (0, 0). | | | | ticTacToe.move(0, 2, 2); // return 0 (no one wins) |X| |O| | | | | // Player 2 makes a move at (0, 2). | | | | ticTacToe.move(2, 2, 1); // return 0 (no one wins) |X| |O| | | | | // Player 1 makes a move at (2, 2). | | |X| ticTacToe.move(1, 1, 2); // return 0 (no one wins) |X| |O| | |O| | // Player 2 makes a move at (1, 1). | | |X| ticTacToe.move(2, 0, 1); // return 0 (no one wins) |X| |O| | |O| | // Player 1 makes a move at (2, 0). |X| |X| ticTacToe.move(1, 0, 2); // return 0 (no one wins) |X| |O| |O|O| | // Player 2 makes a move at (1, 0). |X| |X| ticTacToe.move(2, 1, 1); // return 1 (player 1 wins) |X| |O| |O|O| | // Player 1 makes a move at (2, 1). |X|X|X|
Could you trade extra space such that move() operation can be done in O(1)?
Hide Hint 2
You need two arrays: int rows[n], int cols[n], plus two variables: diagonal, anti_diagonal.
class TicTacToe(object):
def __init__(self, n):
self.row, self.col, self.diag, self.anti_diag, self.n = [0] * n, [0] * n, 0, 0, n
def move(self, row, col, player):
offset = player * 2 - 3
self.row[row] += offset
self.col[col] += offset
if row == col:
self.diag += offset
if row + col == self.n - 1:
self.anti_diag += offset
if self.n in [self.row[row], self.col[col], self.diag, self.anti_diag]:
return 2
if -self.n in [self.row[row], self.col[col], self.diag, self.anti_diag]:
return 1
return 0
공유하기
'[영문사이트] LeetCode 리트코드/[Medium]Top Interview Questions' 의 관련글
-
Others - Top Interview Questions[Medium] (9/9) : Python 2020.12.22더보기
-
Math - Top Interview Questions[Medium] (8/9) : Python 2020.12.22더보기
-
Dynamic Programming - Top Interview Questions[Medium] (6/9) : Python 2020.12.22더보기
-
Sorting and Searching - Top Interview Questions[Medium] (5/9) : Python 2020.12.22더보기