173. Binary Search Tree Iterator
leetcode.com/problems/binary-search-tree-iterator/
1번과 2번은 공간복잡도에서 차이가 있기 때문에 2번을 선택해야한다. 1번은 모든 노드를 저장하고 2번은 노드의 높이만큼 저장한다. 물론 기울어진 트리의 경우에는 같다.
173. Binary Search Tree Iterator
Medium
3097288Add to ListShare
Implement the BSTIterator class that represents an iterator over the in-order traversal of a binary search tree (BST):
- BSTIterator(TreeNode root) Initializes an object of the BSTIterator class. The root of the BST is given as part of the constructor. The pointer should be initialized to a non-existent number smaller than any element in the BST.
- boolean hasNext() Returns true if there exists a number in the traversal to the right of the pointer, otherwise returns false.
- int next() Moves the pointer to the right, then returns the number at the pointer.
Notice that by initializing the pointer to a non-existent smallest number, the first call to next() will return the smallest element in the BST.
You may assume that next() calls will always be valid. That is, there will be at least a next number in the in-order traversal when next() is called.
Example 1:

Input ["BSTIterator", "next", "next", "hasNext", "next", "hasNext", "next", "hasNext", "next", "hasNext"] [[[7, 3, 15, null, null, 9, 20]], [], [], [], [], [], [], [], [], []] Output [null, 3, 7, true, 9, true, 15, true, 20, false] Explanation BSTIterator bSTIterator = new BSTIterator([7, 3, 15, null, null, 9, 20]); bSTIterator.next(); // return 3 bSTIterator.next(); // return 7 bSTIterator.hasNext(); // return True bSTIterator.next(); // return 9 bSTIterator.hasNext(); // return True bSTIterator.next(); // return 15 bSTIterator.hasNext(); // return True bSTIterator.next(); // return 20 bSTIterator.hasNext(); // return False
Constraints:
- The number of nodes in the tree is in the range [1, 105].
- 0 <= Node.val <= 106
- At most 105 calls will be made to hasNext, and next.
Follow up:
- Could you implement next() and hasNext() to run in average O(1) time and use O(h) memory, where h is the height of the tree?
Solution
Before looking at the solutions for this problem, let's try and boil down what the problem statement essentially asks us to do. So, we need to implement an iterator class with two functions namely next() and hasNext(). The hasNext() function returns a boolean value indicating whether there are any more elements left in the binary search tree or not. The next() function returns the next smallest element in the BST. Therefore, the first time we call the next() function, it should return the smallest element in the BST and likewise, when we call next() for the very last time, it should return the largest element in the BST.
You might be wondering as to what could be the use case for an iterator. Essentially, an iterator can be used to iterate over any container object. For our purpose, the container object is a binary search tree. If such an iterator is defined, then the traversal logic can be abstracted out and we can simply make use of the iterator to process the elements in a certain order.
1. new_iterator = BSTIterator(root); 2. while (new_iterator.hasNext()) 3. process(new_iterator.next());
Now that we know the motivation behind designing a good iterator class for a data structure, let's take a look at another interesting aspect about the iterator that we have to build for this problem. Usually, an iterator simply goes over each of the elements of the container one by one. For the BST, we want the iterator to return elements in an ascending order.
An important property of the binary search tree is that the inorder traversal of a BST gives us the elements in a sorted order. Thus, the inorder traversal will be the core of the solutions that we will look ahead.

4 / 19
Approach 1: Flattening the BST
Intuition
In computer programming, an iterator is an object that enables a programmer to traverse a container, particularly lists. This is the Wikipedia definition of an iterator. Naturally, the easiest way to implement an iterator would be on an array like container interface. So, if we had an array, all we would need is a pointer or an index and we could easily implement the two required functions next() and hasNext().
Hence, the first approach that we will look at is based on this idea. We will be using additional memory and we will flatten the binary search tree into an array. Since we need the elements to be in a sorted order, we will do an inorder traversal over the tree and store the elements in a new array and then build the iterator functions using this new array.
Algorithm
- Initialize an empty array that will contain the nodes of the binary search tree in the sorted order.
- We traverse the binary search tree in the inorder fashion and for each node that we process, we add it to our array nodes. Note that before processing a node, its left subtree has to be processed (or recursed upon) and after processing a node, its right subtree has to be recursed upon.
- Once we have all the nodes in an array, we simply need a pointer or an index in that array to implement the two functions next and hasNext. Whenever there's a call to hasNext, we simply check if the index has reached the end of the array or not. For the call to next function, we simply return the element pointed by the index. Also, after a the next function call is made, we have to move the index one step forward to simulate the progress of our iterator.

/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class BSTIterator {
ArrayList<Integer> nodesSorted;
int index;
public BSTIterator(TreeNode root) {
// Array containing all the nodes in the sorted order
this.nodesSorted = new ArrayList<Integer>();
// Pointer to the next smallest element in the BST
this.index = -1;
// Call to flatten the input binary search tree
this._inorder(root);
}
private void _inorder(TreeNode root) {
if (root == null) {
return;
}
this._inorder(root.left);
this.nodesSorted.add(root.val);
this._inorder(root.right);
}
/**
* @return the next smallest number
*/
public int next() {
return this.nodesSorted.get(++this.index);
}
/**
* @return whether we have a next smallest number
*/
public boolean hasNext() {
return this.index + 1 < this.nodesSorted.size();
}
}
Complexity analysis
- Time complexity : O(N) is the time taken by the constructor for the iterator. The problem statement only asks us to analyze the complexity of the two functions, however, when implementing a class, it's important to also note the time it takes to initialize a new object of the class and in this case it would be linear in terms of the number of nodes in the BST. In addition to the space occupied by the new array we initialized, the recursion stack for the inorder traversal also occupies space but that is limited to O(h) where hh is the height of the tree.
- next() would take O(1)
- hasNext() would take O(1)
- Space complexity : O(N) since we create a new array to contain all the nodes of the BST. This doesn't comply with the requirement specified in the problem statement that the maximum space complexity of either of the functions should be O(h) where hh is the height of the tree and for a well balanced BST, the height is usually logNlogN. So, we get great time complexities but we had to compromise on the space. Note that the new array is used for both the function calls and hence the space complexity for both the calls is O(N).
- BST의 모든 노드를 포함하는 새로운 어레이를 생성하기 때문에 O(N) 이는 두 기능 중 하나의 최대 공간 복잡도가 O(h)여야 한다는 문제 진술에 명시된 요건과 맞지 않는다. 여기서 hh는 나무의 높이여야 하며, 균형 잡힌 BST의 경우 높이는 대개 logNlogN이다. 그래서 우리는 엄청난 시간적 복잡성을 얻었지만 우리는 공간을 절충해야 했다. 새 배열이 함수 호출에 모두 사용되므로 두 호출의 공간 복잡성은 O(N)이다.
Approach 2: Controlled Recursion
Intuition
The approach we saw earlier uses space which is linear in the number of nodes in the binary search tree. However, the reason we had to resort to such an approach was because we can control the iteration over the array. We can't really pause a recursion in between and then start it off sometime later.
However, if we could simulate a controlled recursion for an inorder traversal, we wouldn't really need to use any additional space other than the space used by the stack for our recursion simulation.
So, this approach essentially uses a custom stack to simulate the inorder traversal i.e. we will be taking an iterative approach to inorder traversal rather than going with the recursive approach and in doing so, we will be able to easily implement the two function calls without any other additional space.
Things however, do get a bit complicated as far as the time complexity of the two operations is concerned and that is where we will spend a little bit of time to understand if this approach complies with all the asymptotic complexity requirements of the question. Let's move on to the algorithm for now to look at this idea more concretely.
Algorithm
-
Initialize an empty stack S which will be used to simulate the inorder traversal for our binary search tree. Note that we will be following the same approach for inorder traversal as before except that now we will be using our own stack rather than the system stack. Since we are using a custom data structure, we can pause and resume the recursion at will.
-
Let's also consider a helper function that we will be calling again and again in the implementation. This function, called _inorder_left will essentially add all the nodes in the leftmost branch of the tree rooted at the given node root to the stack and it will keep on doing so until there is no left child of the root node. Something like the following code:
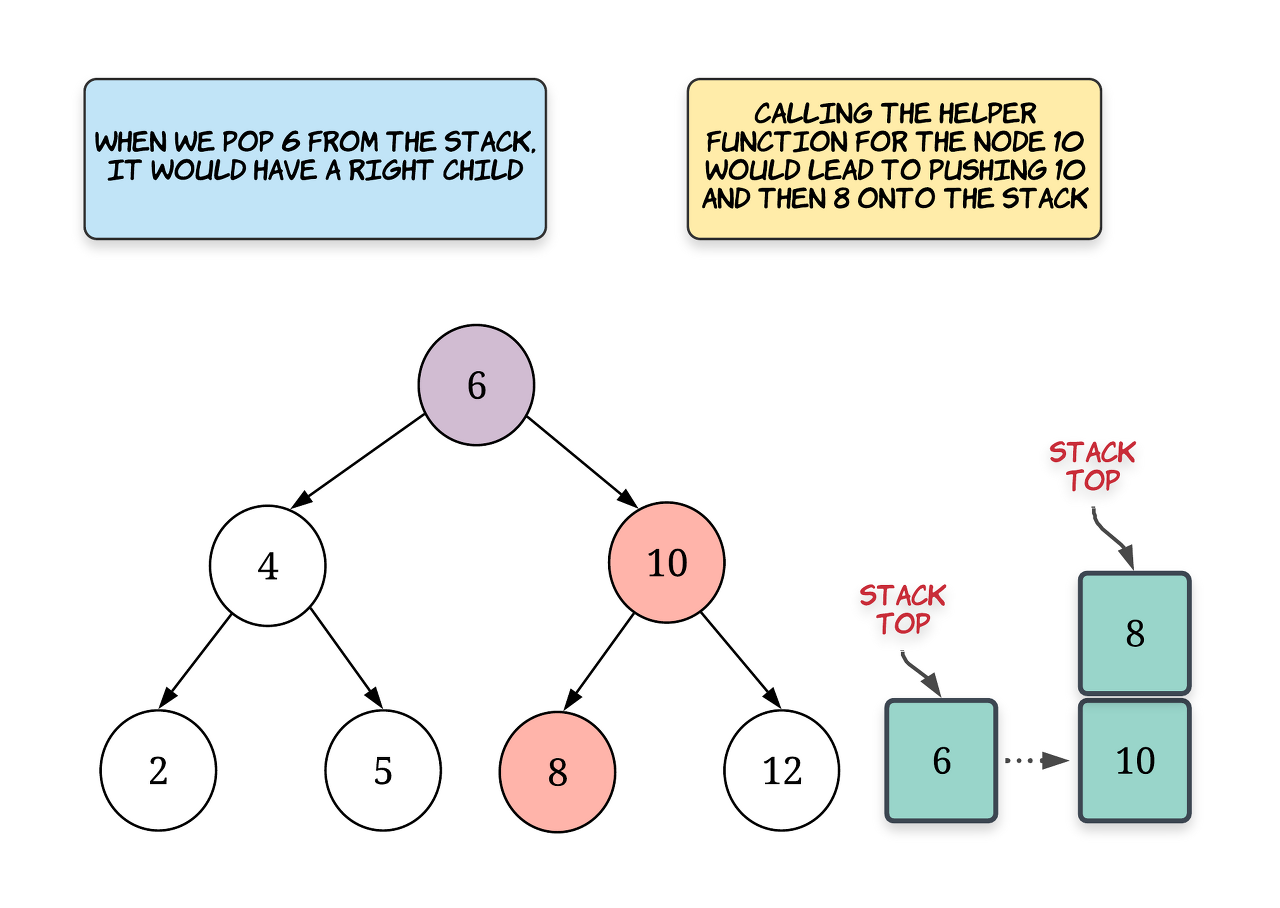
def inorder_left(root): while (root): S.append(root) root = root.leftFor a given node root, the next smallest element will always be the leftmost element in its tree. So, for a given root node, we keep on following the leftmost branch until we reach a node which doesn't have a left child and that will be the next smallest element. For the root of our BST, this leftmost node would be the smallest node in the tree. Rest of the nodes are added to the stack because they are pending processing. Try and relate this with a dry run of a simple recursive inorder traversal and things will make a bit more sense.
-
The first time next() function call is made, the smallest element of the BST has to be returned and then our simulated recursion has to move one step forward i.e. move onto the next smallest element in the BST. The invariant that will be maintained in this algorithm is that the stack top always contains the element to be returned for the next() function call. However, there is additional work that needs to be done to maintain that invariant. It's very easy to implement the hasNext() function since all we need to check is if the stack is empty or not. So, we will only focus on the next() call from now.
-
Initially, given the root node of the BST, we call the function _inorder_left and that ensures our invariant holds. Let's see this first step with an example.

-
Suppose we get a call to the next() function. The node which we have to return i.e. the next smallest element in the binary search tree iterator is the one sitting at the top of our stack. So, for the example above, that node would be 2 which is the correct value. Now, there are two possibilities that we have to deal with:
-
One is where the node at the top of the stack is actually a leaf node. This is the best case and here we don't have to do anything. Simply pop the node off the stack and return its value. So, this would be a constant time operation.
-
Second is where the node has a right child. We don't need to check for the left child because of the way we have added nodes onto the stack. The topmost node either won't have a left child or would already have the left subtree processed. If it has a right child, then we call our helper function on the node's right child. This would comparatively be a costly operation depending upon the structure of the tree.
-
-
We keep on maintaining the invariant this way in the function call for next and this way we will always be able to return the next smallest element in the BST from the top of the stack. Again, it's important to understand that obtaining the next smallest element doesn't take much time. However, some time is spent in maintaining the invariant that the stack top will always have the node we are looking for.
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class BSTIterator {
Stack<TreeNode> stack;
public BSTIterator(TreeNode root) {
// Stack for the recursion simulation
this.stack = new Stack<TreeNode>();
// Remember that the algorithm starts with a call to the helper function
// with the root node as the input
this._leftmostInorder(root);
}
private void _leftmostInorder(TreeNode root) {
// For a given node, add all the elements in the leftmost branch of the tree
// under it to the stack.
while (root != null) {
this.stack.push(root);
root = root.left;
}
}
/**
* @return the next smallest number
*/
public int next() {
// Node at the top of the stack is the next smallest element
TreeNode topmostNode = this.stack.pop();
// Need to maintain the invariant. If the node has a right child, call the
// helper function for the right child
if (topmostNode.right != null) {
this._leftmostInorder(topmostNode.right);
}
return topmostNode.val;
}
/**
* @return whether we have a next smallest number
*/
public boolean hasNext() {
return this.stack.size() > 0;
}
}
Complexity analysis
-
Time complexity : The time complexity for this approach is very interesting to analyze. Let's look at the complexities for both the functions in the class:
-
hasNext is the easier of the lot since all we do in this is to return true if there are any elements left in the stack. Otherwise, we return false. So clearly, this is an O(1)O(1) operation every time. Let's look at the more complicated function now to see if we satisfy all the requirements in the problem statement
-
next involves two major operations. One is where we pop an element from the stack which becomes the next smallest element to return. This is a O(1) operation. However, we then make a call to our helper function _inorder_left which iterates over a bunch of nodes. This is clearly a linear time operation i.e. O(N) in the worst case. This is true.
However, the important thing to note here is that we only make such a call for nodes which have a right child. Otherwise, we simply return. Also, even if we end up calling the helper function, it won't always process N nodes. They will be much lesser. Only if we have a skewed tree would there be N nodes for the root. But that is the only node for which we would call the helper function.
- Thus, the amortized (average) time complexity for this function would still be O(1) which is what the question asks for. We don't need to have a solution which gives constant time operations for every call. We need that complexity on average and that is what we get.
-
-
Space complexity: The space complexity is O(N) (N is the number of nodes in the tree), which is occupied by our custom stack for simulating the inorder traversal. Again, we satisfy the space requirements as well as specified in the problem statement.
공간 복잡성 : 공간 복잡성은 O (N) (N은 트리의 노드 수)이며, 이는 주문형 트래버설을 시뮬레이션하기 위해 우리의 사용자 스택에 의해 점유됩니다. 다시 말하지만, 우리는 문제 진술서에 명시된 것뿐만 아니라 공간 요건을 충족한다.
amortize [ˈæmərtaɪz]
동사1. [상업](빚을) 분할 상환하다